Hey! I recorded a video course!
If you like this article, you will also like the course! Check it out here!
Hey everyone,
Today’s article is sponsored by Tigris. They were so kind to give me beta access to their globally distributed S3-compatible Object Storage before their public beta launch. Tigris partners with Fly.io to distribute your files globally, which makes accessing them anywhere in the world super fast. Tigris is an excellent drop-in solution if you use S3 and give users access to your files.
I tried out Tigris and was quite impressed. The following blog post contains my experience and a detailed walkthrough of how to integrate Tigris into your Elixir application. Let’s get started!
🔗 What’s Tigris
The advantage of Tigris is that it allows low-latency access to your files anywhere in the world. That means users can download files from your server fast, regardless of location. But why is that important?
Usually, when you set up an S3 bucket, you choose only one location to host your files. That means you store all your files in one region. Now, if a user from Australia wants to download a file from your server located in e.g. Amsterdam, the download request travels from Australia to Europe and back. That can take a second or more, which creates a horrible user experience for your Australian user. It would be better if a copy of the file was stored in Australia too. That way, the request stays within the region, which makes it super fast and the user super happy. That’s where Tigris comes in.
Tigris takes over the complex and tedious work of replicating your file in more than one location. When you upload a file, it first stays in the region where you uploaded it. But if a user from another region requests the file, it gets replicated and cached in the other region as well. That way, the file is available as close to the users as possible.
Tigris partners with Fly.io to achieve this replication. Fly is well-known for drastically simplifying the process of running your application in all regions of the world. Tigris uses Fly’s infrastructure to store your files in currently ten regions* but plans to expand the network to all 35 regions served by Fly. It is independent of the regions where you deploy your fly apps. So, even if your app only runs in one region, Tigris will cache your files in all available regions.
This all sounds very complicated, but luckily, the setup is super simple. Tigris mimics the AWS S3 API, so any library that works with S3 also works with Tigris. If you use S3 already with e.g. ExAws.S3, you only have to change a few settings. Let’s have a look.
The ten regions are Frankfurt, Sao Paulo, Ashburn (US), Johannesburg, London, Madrid, Chicago, Singapore, San Jose, and Sydney
🔗 The Setup
As a demo project, I created a small image guessing game called RecIt. You can find the demo deployed on Fly.io and the code on GitHub.
The game is simple: Select the category of sport you see in an image.
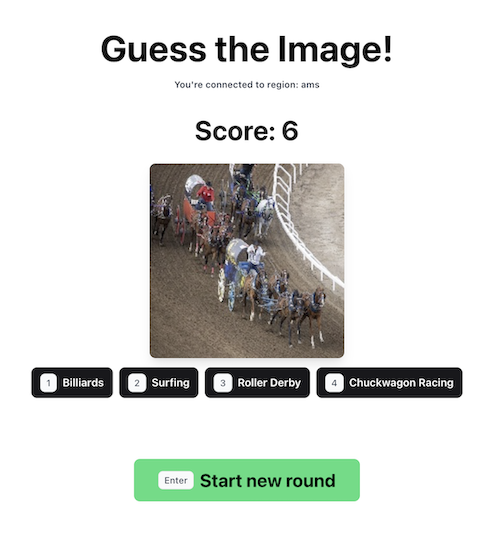
Both speed and correctness are important. The faster you categorize the image, the better. That means our application must show the image as fast as possible. Otherwise, players from regions with faster access to the images have an unfair advantage. Let’s see how we can use Tigris to make file access fast for users everywhere.
🔗 Add a Tigris Bucket
First, we create a new application with mix phx.new recit and deploy it to Fly with fly launch. Now, we can add the S3 bucket managed by Tigris. The following steps are from the official Get Started guide.
First, we need to add our bucket to Fly. Run this and follow the instructions:
fly storage create
If you add a Tigris bucket from inside a fly project, it will automatically add it to the fly app and won’t reveal the environment variables you need to access it. That’s good for production but not so great for local development. Let’s add another bucket for local development. Run the following, and Tigris will reveal the environment variables at the end of the command:
> cd .. && fly storage create
➜ Development fly storage create
? Select Organization: Your Organization
? Choose a name, use the default, or leave blank to generate one: my-dev-bucket
Your Tigris project (my-dev-bucket) is ready. See details and next steps with: https://fly.io/docs/reference/tigris/
Set one or more of the following secrets on your target app.
BUCKET_NAME: my-dev-bucket
AWS_ENDPOINT_URL_S3: https://fly.storage.tigris.dev
AWS_ACCESS_KEY_ID: tid_your-access-key
AWS_SECRET_ACCESS_KEY: tsec_your-secret-access-key
AWS_REGION: auto
Don’t forget to copy & paste the environment variables into a .env file. Now, we can start developing locally.
🔗 Connect to the Tigris Bucket
Tigris provides instructions for many different languages on how to connect to their buckets. The following steps are from the Elixir guide:
First, we need to add the dependencies to mix.exs:
# mix.exs
defp deps do
# other dependencies
{:ex_aws, "~> 2.0"},
{:ex_aws_s3, "~> 2.0"},
{:hackney, "~> 1.9"},
{:sweet_xml, "~> 0.6.6"},
# The official docs list this
# but it's not needed because
# we use Jason instead.
# {:poison, "~> 3.0"},
# Might exist already
# Phoenix adds it by default
{:jason, "~> 1.1"}
end
Next, we add the ex_aws configuration to our runtime.exs. This step deviates from the official instructions where you add duplicate settings to dev.exs and runtime.exs. This is a simpler setup:
# config/runtime.exs
if config_env() != :test do
config :ex_aws,
# Consider setting this to config_env() != :prod
# if you don't want to debug your requests in production
debug_requests: true,
json_codec: Jason,
access_key_id:
System.get_env("AWS_ACCESS_KEY_ID") ||
raise("Missing env variable: AWS_ACCESS_KEY_ID"),
secret_access_key:
System.get_env("AWS_SECRET_ACCESS_KEY") ||
raise("Missing env variable: AWS_SECRET_ACCESS_KEY")
config :ex_aws, :s3,
scheme: "https://",
host: "fly.storage.tigris.dev",
region: "auto",
# This extra config is useful if you only want to work
# with one bucket in your application. If not, remove it.
bucket:
System.get_env("BUCKET_NAME") ||
raise("Missing env variable: BUCKET_NAME")
end
Now, restart your terminal and start the development server with iex -S mix phx.server. Let’s test the bucket connection.
iex> ExAws.S3.list_buckets() |> ExAws.request!()
%{
body: %{
buckets: [
%{name: "my-prod-bucket"},
%{name: "my-dev-bucket"}
]
}
}
Surprisingly, we can see both the production and development buckets, although we used the environment variables of the development bucket. This is because we created both buckets with the same Fly account organization. If we had chosen different organizations, we wouldn’t see both. But seeing a bucket doesn’t mean we can access it. Let’s try to list the objects of the production bucket. It won’t work:
iex> ExAws.S3.list_objects("my-prod-bucket") |> ExAws.request()
{:error,
{:http_error, 403,
%{
body: "<some xml>Access Denied.<more xml>",
headers: _headers,
status_code: 403
}}}
So, the access control works as expected. If we use the environment variables of the dev bucket, we can’t access the prod bucket and vice-versa. All good.
🔗 Upload a File
Now that we have a working connection to our S3 bucket managed by Tigris, let’s upload some images for our game.
To make the file upload and download easier, I wrote a little wrapper around ExAws. You can find it on GitHub. The wrapper exposes simple upload/2 and download/1 functions. Let’s give it a try:
iex> file = File.read!("./data/valid/air hockey/1.jpg")
<<255, 216, 255, ...>>
iex> Recit.Storage.upload("test.jpg", file)
{:ok, %{status_code: 200}}
iex> Recit.Storage.download("test.jpg")
{:ok, %{body: <<255, 216, 255, ...>>, status_code: 200}}
It works, great. Now, let’s upload all images of our game.
🔗 Upload many Files
I used a dataset of 500 images of 100 sports to seed images for the RecIt guessing game. You can find it on GitHub.
Now, the challenge is uploading all 500 images to our S3 bucket. AWS S3 doesn’t offer an “upload multiple files at once” endpoint, so Tigris doesn’t either. However, in S3, you can upload a complete folder using their UI. Tigris provides a handy dashboard of your buckets but has no folder upload (yet). If you’re interested in the dashboard, you can open it with fly storage dashboard.
I wrote a Mix Task that uploads the files 1-by-1. It’s not perfect, but it works. If you want to migrate a lot of data to Tigris, I suggest you use their data migration command instead.
Next, we need the environment variables of the production bucket to upload the images. Fly doesn’t reveal the environment variables of your machines, but we can create a remote IEx connection to your Elixir application and read them out anyway.
# Open a SSH tunnel to your machine
fly ssh console
# Start a remote IEx session
bin/my-app remote
# Print the ExAws config
Application.get_all_env(:ex_aws)
Now we copy and paste both AWS_* variables to our local .env file, restart the terminal, and run mix upload_data. The upload process takes around 2 minutes.
🔗 Testing the Latency
Now that we have a working game at rec-it.fly.dev, we can test the latency benefit that Tigris promises.
I tested the latency in 4 regions with a simple test setup. First, I hard-coded the images that the game returns. This allowed me to record how long a file download took before and after caching. Whenever a new image appeared, I wrote down the download time as reported in the Network tab of my browser. I used NordVPN to switch through 4 regions and recorded the download times in each. I changed my NordVPN server three times in every region to account for latency differences caused by a slow server.
This setup is far from perfect and not scientific, but it gives us a rough indication of the performance increase we could expect.
At first, I had to guess from which region Tigris served my file. I contacted the co-founder and CEO of Tigris, Ovais Tariq, and after just a few days, they added a special Tigris-Object-Header to the response, which shows the region from which they served a file. Try getting that level of support from AWS!
Back to the test setup. I assumed that the first time I downloaded an image, Tigris would serve it from the region where I uploaded it, Amsterdam. That means that in regions other than Amsterdam, the download time would be quite long for the first request but speed up significantly with the second request because Tigris cached the file in the new region. That’s indeed what happened. Below are the average download times for the first and second requests. The raw data is on GitHub.
| Client Location | Avg. Time of 1st Request | Avg. Time of 2nd Request (Cached) |
|---|---|---|
| Amsterdam, NL | 24ms | 23ms |
| Sydney, AUS | 863ms | 340ms (-60%) |
| Dallas, USA | 406ms | 188ms (-55%) |
| Sao Paulo, BR | 728ms | 297ms (-60%) |
As you can see, the differences are significant. Tigris decreased the time it took to download a file by 55-60% in all three regions! And all I had to do was change a few lines of my ExAws configuration.
One option I haven’t tried is the Cache on write configuration, which should eliminate the latency difference between the first and second requests. If you set that option, Tigris will cache your files proactively even before a user requests it from another region. I assume this option will significantly increase your invoice, so use it only if necessary.
🔗 Conclusion
I must admit that I was quite impressed by Tigris. Switching to it from S3 took only a small code change, their documentation is exhaustive, and their team is very supportive and responsive. I can’t see a difference between their pricing and S3’s pricing except for the data transfer between regions, which was not finalized at the time of writing. Once they are out of beta, I will certainly consider them for storing files in production applications.
And that’s it! I hope you enjoyed this article! If you want to support me, check out my latest startup Indie Courses or video course. Follow me on Twitter or subscribe to my newsletter below if you want to get notified when I publish the next blog post. Until the next time! Cheerio 👋